Machine Learning Projects: Is it really hard to Manage?
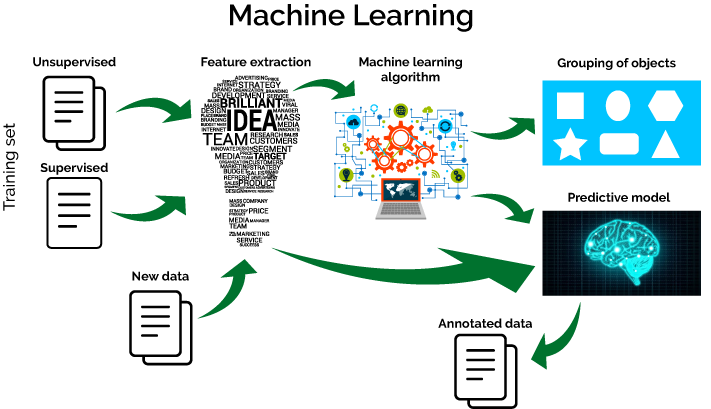
Machine Learning is one of must buzzing word in IT industry now days. Machine learning is a process of extracting knowledge from the large volume of data. Machine learning processes can make a computer system enable to provide predictions or sometimes even take some decisions. Such decision making capabilities are built on knowledge base of using historical data. Machine learning systems can make decisions without being explicitly programmed. Machine learning uses a huge volume of structured and semi-structured data so that a machine learning model can generate accurate result or give predictions based on that data. Such models works on the basis of algorithms which use historical data and learn from these data and decided further course of action in real world problems. However such machine learning models are highly domain specific i.e. a model developed for a domain can only serve the purposes of that particular domain. For example, if we create a machine learning model to detect a cat, it will only give results for images of cat and if we try to provide data of something different like goat then the model will be unresponsive.
What all takes for a ML Project?
A professional level project of Machine Learning (ML) takes lots of inputs in terms of data and various mathematical models. A single person can also run a team for ML project and there may be couple of team members and the decision of number of persons to be involved largely depends on scale of project. However if we compare the success or failure rates of ML projects and other IT software projects, the first one has higher failure rate. What make a ML project fails and what are the factors which may cause a failure is a big question in mind of students and early data scientists.
Reasons of ML projects Failures
- Uncertainty – ML and AI projects are initiated with a conceptual thought i.e. dream and many times dreams are not fulfilled. For example, what will be accuracy for predicting sentiments of people? At the beginning of such ML project, development team cannot predict about the accuracy of ML model for accurate predictions.
- Prone to fail unexpectedly – The machines which are built on the basis of computational sciences are very much prone to fail unexpectedly and occasionally. For example, if we develop a robot for image classification then it may fail to recognize images as intelligently as a photographer can do. My robot wouldn’t necessarily look right at an object in the same way a human photographer would. Humans likely not even notice the difference but modern deep learning networks suffered a lot.
- Need of Training Data– Machine learning models works better when we have lots of training data. Training data can be understood as data which is known i.e. its category, classification details are with the data. It is said that more training data we have, the greater chances to develop a model with better accuracy rate.
How to deal with problems
- Attention to training data – Mislabeling, wrong classification or strong edge cases may lead to wrong model development in ML models. In order to cope with such problems is to focus more on training data preprocessing which can prevent the most of failure. For many use cases, it’s very doubtful that a training model will be proved better than the rate at which two independent humans agree.
- Technical state of the art (SOTA) – ML project delivery decisions must be based on technical state of the art (SOTA) which relies on actualization of team, resources and capacities. The decision made on the basis of business values and hypothetical statements are many time prone to failure.
- Necessary But Not Sufficient – Let’s think of the organization which does not have prior Artificial Intelligence (AI) exposure. Therefore, the first recruit of your team should not be a data scientist. Rather, your first hire must be a data engineer. A data scientist’s role is to investigate data for insights. A data engineer’s role is to create the data set. Before investigating data, we need to make data models which are equally complex as to investigate the data.
- Handling failures – All machine learning models are tending to get failed for a reasonable number of the time, and how this is being handled makes a difference. The ML models often have a reliable confidence value that can be used to for this purpose. With batch data processes, we have an option to build human-in-the-loop systems which can be used to send low confidence predictions to an operator to make the system work reliably end to end and collect high-quality training data. In some other use cases, we can present low confident predictions in form of flagging the potential errors.
Conclusion
The aim of machine learning was mostly to make smart decisions with better capacity to handle competition from competitors, but more and more we are putting our efforts to use machine learning into products and services we use. As we are banking upon more and more on ML algorithms, machine learning is taking a shape of an engineering discipline and also a research domain. Machine learning projects are adopted by organizations with a hope of better Return of Investments (ROI) in later stage and it also involved with huge costing. Therefore success and failure of ML projects has a big role in the success and failure of an organization. Therefore, above mentioned measurements should be taken for making a better control over the ML projects, its diversities and leading to a successful completion of the same.
Author –
Prof. Dr. Sandeep Kautish
Dean Academics
LBEF Campus